Mon voyage au pays de la DATA - épisode 1

A la découverte des produits Data Science et du rôle de Data Product Owner

{kind=link}
Mon voyage au pays de la DATA - épisode 1
Lorsque Gutenberg a inventé l’imprimerie, il a été le catalyseur de la diffusion massive d’un nouveau média “Le livre imprimé”. Il s’agit d’une refonte radicale de notre rapport à l’information.
Alors que la technologie de Gutenberg se répandait à travers le monde, les bibliothèques ont relevé le défi de catégoriser et d’organiser tous les nouveaux types de données qui étaient désormais disponibles. Aujourd’hui, près de 600 ans plus tard, nous sommes à un point d’inflexion similaire avec l’avènement des technologies de la donnée et plus récemment les LLM (Large Language Models, qui incluent les outils de type ChatGPT).
Comme toute innovation technologique digne de ce nom, cette révolution nommée Data s’est accompagnée et s’accompagne encore par la création d’un florilège de nouveaux métiers, de nouveaux process, de nouvelles méthodes, de nouveaux termes …. Data engineer, Data analyst, MLOPS, Data scientist, Data Product Owner, Stewart, Prompt engineer…
Néophyte comme je l’étais encore il y a moins de deux ans, j’ai décidé de vous ouvrir mon carnet de bord pour vous faire profiter de mon voyage dans l’univers de la Data. Moi qui ai développé mes réflexes et bonnes pratiques produits dans un autre domaine, j’ai dû sauter dans le grand bain et apprendre à me débrouiller dans ce nouveau monde des produits data science… ceci est le récit de mon voyage en territoire inconnu.
Si vous êtes, comme moi, en quête d’apprentissage et de partage d’expérience sur les produits à forte composante DATA, cet article est une bonne première étape.
C’est quoi un produit Data Science ?
Un produit Data Science est un produit dont le cœur de la proposition de valeur repose sur la donnée et est apportée à l’utilisateur grâce au Machine Learning.
On peut citer par exemple les algorithmes de recommandations que vous retrouvez sur des plateformes de type Amazon, Netflix ou Spotify. Ces “petites choses magiques” qui vous suggèrent votre prochain achat, votre prochain film à regarder ou votre prochaine chanson à écouter, le calcul des temps de trajets et l’optimisation des meilleurs itinéraires en fonction du moment de la journée sur WAZE ou encore Citymapper, les innombrables chatbots ou plus récemment le fameux ChatGPT, sont autant d’exemples de produits et features Data Science que nous avons adoptés sans même nous en rendre compte.

Quelles différences avec un produit classique ?
1. Un produit data repose sur des données et… il existe une véritable incertitude quant aux données !
Ces incertitudes sont à la fois techniques (les données sont-elles disponibles ? Quel est leur niveau de qualité voire de fiabilité ?) et métier (avons-nous la capacité d’atteindre des résultats suffisants pour apporter de la valeur sur un sujet de prédiction ? La taille de l’échantillon est-elle représentative ?).
Ces incertitudes nécessitent d’investir du temps sur des explorations de données et des expérimentations, ce qui peut modifier le rythme de delivery par rapport un un produit classique. C’est à dire que vous ne pouvez pas savoir avant d’essayer où la technologie et ou la donnée vous mèneront… Vous ne pouvez pas définir 100% des spécifications à l’avance.
2. Exploiter les données, pas si simple que ça !
En effet, pour pouvoir exploiter des données, il faut d’abord :
- Les récupérer
- Les stocker
- Les nettoyer
- Les exposer
- Les protéger et les gouverner
Ce travail est long et va nécessiter d’avoir dès le début des réflexions et discussions concernant le traitement à appliquer aux données. Cette phase nécessite également une forte acculturation technique au traitement, nettoyage, stockage et exploitation des données pour tous les membres de l’équipe, mais aussi aux sujets de gouvernance et de sécurité de la donnée, ce qui n’est pas toujours le cas pour un produit classique. La compréhension de tous ces enjeux est un des piliers de la réussite du produit.
C’est ce traitement préalable qui va permettre de transformer une simple donnée en une information utilisable pour pouvoir comprendre son produit et prendre des décisions.
3. Un produit data nécessite des profils data
Ces nouveaux profils peuvent impacter l’organisation et le rythme de l’équipe, notamment du fait de la place de l’expérimentation mentionnée plus haut.

Voici quelques-uns des rôles clés dans une équipe DATA :
Data Engineer : Les ingénieurs de données construisent et maintiennent l’infrastructure de données qui permet à une organisation de stocker, de gérer et d’analyser de grandes quantités de données. Ils sont responsables de la conception et de la mise en place des bases de données, ainsi que du développement des pipelines de données.
Machine Learning Engineer (MLE): Un machine learning engineer se concentre sur le développement de modèles d’apprentissage automatique qui utilisent les données collectées par les data engineers. Ils travaillent sur la construction, le déploiement et l’optimisation de modèles d’apprentissage automatique. Cela comprend la sélection des algorithmes appropriés, la préparation des données pour l’apprentissage, l’entraînement et le réglage des modèles, ainsi que l’évaluation de leur performance. Les machine learning engineers doivent également s’assurer que les modèles sont mis en production et fonctionnent de manière fiable dans des environnements réels. ce sont ces pratiques que l’on désigne couramment par le terme “MLOps” et dont les MLEs détiennent la responsabilité partagée avec les Data Engineers
Data Analyst : Les analystes de données effectuent des analyses statistiques des données. Ils transforment les données en informations qui peuvent aider à prendre des décisions d’affaires. Les analystes de données ont généralement de solides compétences en mathématiques et en statistiques, ainsi qu’une bonne compréhension des affaires.
Data Scientist : Les scientifiques de données sont similaires aux analystes de données, mais ils sont généralement plus axés sur la prédiction et l’élaboration de modèles complexes à partir de données. Ils utilisent des techniques de machine learning et d’intelligence artificielle pour interpréter des ensembles de données complexes.
Data Steward : Les intendants de données sont responsables de la qualité, de l’intégrité et de la sécurité des données. Ils mettent en place des politiques et des procédures pour la gestion des données, et s’assurent que les données sont conformes à ces politiques.
Business Intelligence (BI) Analyst : Les analystes de BI utilisent les données pour aider à informer la prise de décision d’affaires. Ils créent des rapports, des tableaux de bord et d’autres outils de visualisation de données pour aider à interpréter les données.
Data Architect : Les architectes de données conçoivent la structure et le schéma des bases de données pour répondre aux besoins spécifiques d’une entreprise. Ils travaillent en étroite collaboration avec les ingénieurs de données et d’autres membres de l’équipe pour s’assurer que les systèmes de données sont structurés de manière à faciliter l’analyse et l’extraction de données.
Prompt Engineer : il s’agit d’une personne chargée de trouver les meilleures manières de parler avec une IA, de lui proposer les meilleures requêtes, ‘prompt’ en anglais, pour qu’ensuite cette même IA vous fournisse la meilleure réponse possible.
L’équation gagnante d’un produit (data) à succès ? Sa capacité à répondre à un besoin
Les deux parties d’un même tout : le fond et la forme ;)
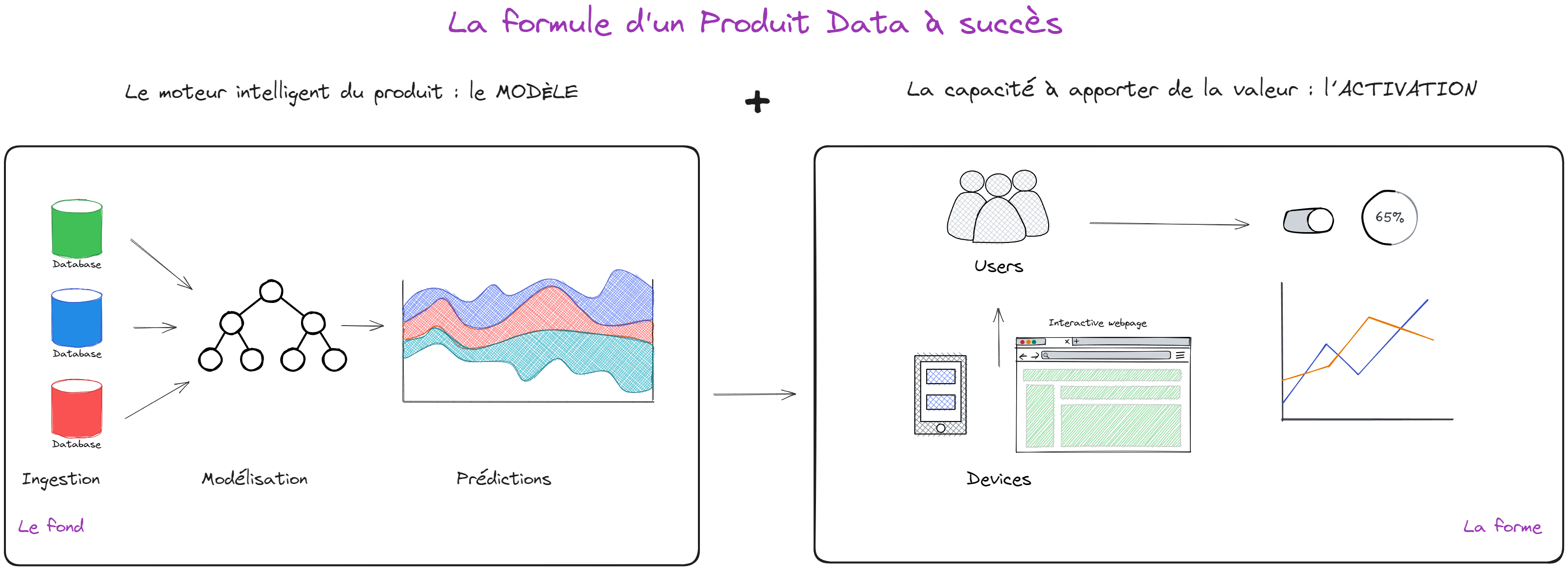
*Inspiré du Techtrends Produits Data Science de Xebia et Thiga
Sur la partie gauche de ce schéma vous trouvez le moteur intelligent du produit : le MODÈLE (le fond)
A partir de données ingérées, un algorithme effectue une prédiction sur une variable cible que l’on cherche à déterminer.
Dans le cas des suggestions Spotify, cette variable cible correspond au fait que l’utilisateur va aimer le titre ou non. Cette partie du produit est au coeur du travail des profils Data de l’équipe.
Sur la partie de droite, vous trouvez ce qu’on appelle L’ACTIVATION, c’est-à- dire le mécanisme à travers lequel la prédiction va apporter de la valeur à l’utilisateur (la forme)
Elle englobe la mise à disposition des résultats du modèle - l’affichage des titres recommandées- et l’activation de ce résultat -le fait de cliquer sur l’un des titres pour l’écouter. Cette partie est principalement sous la responsabilité des équipes de développement.
Pourtant ces deux mondes ne peuvent pas fonctionner en silo. En fonction du type de modèle et de ses performances, l’activation va devoir être adaptée. Il est donc crucial pour un product owner de toujours garder ces deux éléments en tête.
Le Product Management : un rôle déterminant dans les équipes Data aussi
Comme pour tous les produits informatiques dignes de ce nom, il s’agit avant tout de définir la Vision du Produit afin de maximiser la valeur ajoutée et l’impact pour l’entreprise. Il s’agit de travailler avec les parties prenantes, y compris les clients et/ou utilisateurs, les équipes de vente et de marketing, et la direction, pour comprendre les besoins du marché et développer une vision pour le produit qui répond à ces besoins. C’est pourquoi comme pour une équipe de développement classique, la présence d’un product owner et l’adoption d’une approche produit agile est nécessaire malgré le fait qu’elle prenne une forme différente en fonction des contextes..
Les spécificités du rôle du Produit dans une équipe Data
Comme pour le product owner classique, la mission du Data Product owner est de piloter les développements du produit pour arriver à maximiser la valeur apportée aux utilisateurs, mais avec quelques spécificités propres au monde de la data.

- Aligner l’équipe et ses profils variés sur une orientation business et une vision customer centric. Le Data Product owner devra parvenir à comprendre les enjeux de chacun (des experts, des dev, des ops, des métiers) et réussir à aligner ses mondes radicalement différents pour atteindre les objectifs du produit et produire de la valeur.
- Le Data PO doit analyser les performances du modèle comme celles de l’activation. Son objectif sera de prioriser les chantiers, partager cette vision avec l’équipe et co-construire une roadmap qui garde une cohérence entre algorithmie et interface.
- L’un des grands challenges du Data Product Owner est alors d’arbitrer entre itérations rapides (en découpant le scope, diminuant la complexité du modèle, le nombre de sources, etc.) et chantiers exploratoires plus ambitieux qui peuvent radicalement changer la performance du produit et faire évoluer la roadmap.
- Éviter l’effet boite noire et donner à voir via la vulgarisation
- Acculturer les décideurs et les évangéliser sur la valeur ajoutée de la Data Science dans leur quotidien.
La principale difficulté du Data Product Owner : Gérer les écarts de temporalité
La Data Science est une discipline exploratoire. Lorsqu’on s’attaque à un nouveau modèle, on peut difficilement savoir quand on atteindra les performances cibles ; ni même si on les atteindra ! Il est donc d’autant plus facile de perdre de vue l’objectif initial et de se laisser embarquer dans des considérations scientifiques et des débats parfois longs et peu fructueux. Le data product owner va donc devoir incarner le rôle du capitaine sur un bateau, et garder le cap : l’objectif business que l’on cherche à atteindre quoi qu’il arrive. Ce sera à lui de rassembler, d’aligner et de recentrer l’équipe autour de cet objectif. Ce sera à lui aussi de savoir dire stop et de décider d’abandonner, comme un investisseur peut le faire quand il constate que le coût de revient et le ROI présumés ne sont plus alignés.
Comment gérer l’expérimentation dans un delivery de Machine Learning?
Le spike ou la tâche d’exploration
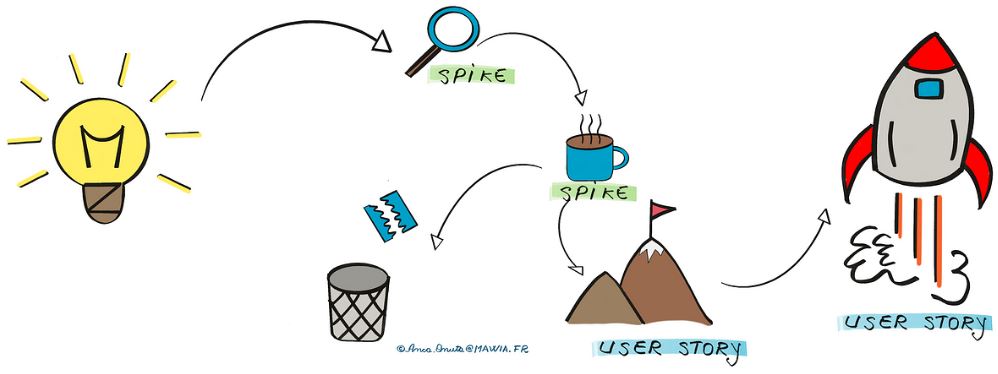
*Schéma proposé par Anca Onuta dans son article Agile in Data Science: How To Split Scope?
L’utilisation des spikes matérialise la phase exploratoire dans le backlog : on détermine avec l’équipe l’investissement à consacrer au sujet, pour cela on définit un temps limité (timebox) et l’objectif du sujet, à quoi sert cette exploration ?
- Acquérir une connaissance
- Lever un risque
- Evaluer un niveau d’incertitude
Penser comme un investisseur
De mon point de vue, il faut penser comme un investisseur et comprendre que si j’investis du temps, je peux gagner mais aussi perdre…
Les expérimentations doivent absolument répondre à une réalité observée sur le terrain et se concentrer sur une hypothèse à vérifier, pas sur une exploration à l’aveugle. Il faut également savoir accepter que certaines expérimentations vont échouer et que ce n’est pas grave. D’autre part il faut aussi savoir accepter que le modèle ne soit pas parfait mais qu’il réponde à un besoin. Il est illusoire de parler de précision du modèle sans mettre en face les gains ou les pertes potentielles. Parfois un modèle très simple et basique apportera plus de valeur ajoutée qu’un modèle complexe et hyper travaillé, ce qui fera la différence c’est le résultat et l’apport au business. Enfin, comme tout travail en équipe, ces expérimentations doivent être cadrées et anticipées pour rester efficaces et éviter les mauvaises surprises.
Conclusion
Voilà que s’achève ce premier épisode de mon voyage au pays de la Data. En conclusion, vous l’aurez compris, un produit data science est un produit avec quelques spécificités mais qui nécessite d’être abordé comme les autres avec une approche produit et un product owner. Le plus grand challenge sera de trouver le bon rythme entre exploration et production sans jamais oublier que le meilleur KPI pour mesurer le succès d’un produit quel qu’il soit est son utilisation.
Des pistes pour les prochains épisodes ?
Comment délivrer un produit Data ? de l’idée au produit en production
Construire et Découper des US Data Science ?
Construire une roadmap Data Science - REX GL
Les basiques de la Data (BDD, Data plateformes, ETL & co…)
Stay tuned !