Les 7 différents types de merge en Git, partie 2/2

Les 7 différents types de merge en Git, partie 2/2
Introduction
Cet article est la partie 2/2 de notre étude des différents types de merge offerts par Git. Pour le contexte et le début de l’étude sur Github, vous pouvez (re)lire la partie 1.
Dans cette seconde partie, nous allons étudier les différentes possibilités offertes Gitlab. Puis nous prendrons un peu de recul et évaluerons les avantages et inconvénients de chaque possibilité étudiée dans les 2 parties.
Comparaison des différents modes de merge : Gitlab & Merge requests
Sur Gitlab, le fonctionnement est un peu différent de celui de Github. Le comportement lors d’un merge est fixé au niveau projet et seule une option (de squash) sera accessible au niveau Merge Request.
Réglages niveau projet et choix lors de la Merge Request
Au niveau projet, dans Settings → Merge requests, nous avons 2 sections intéressantes :
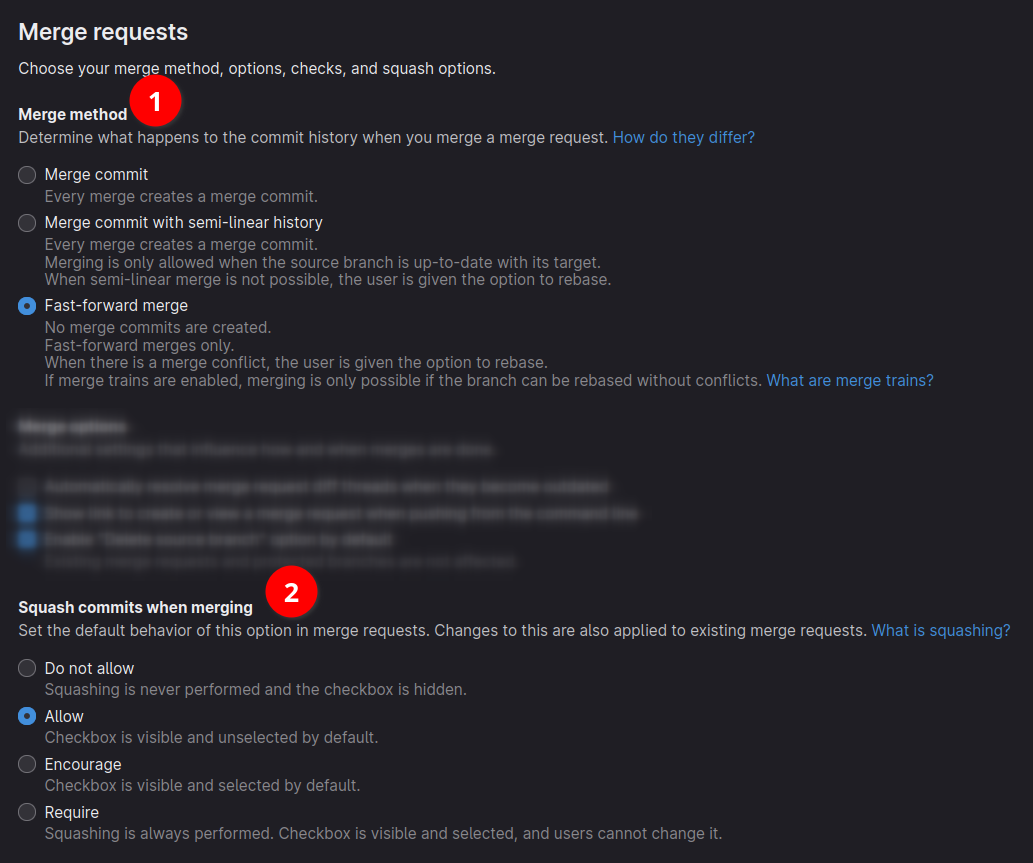
La section 1 détermine de manière exclusive et générale à tout le projet, quel mode de merge sera utilisé, parmi 3 modes.
La section 2 détermine quelle option de squash sera proposée au niveau des Merge Requests (Interdit, optionnel, recommandé, obligatoire).
Et au niveau Merge Request, nous avons donc l’option Squash commits qui sera dans un état en accord avec ce qui a été choisi au niveau projet :
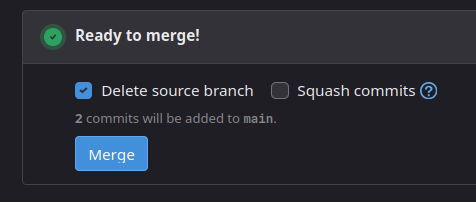
Nous avons donc 3 modes de merge × 2 options = 6 résultats possibles, que nous allons étudier.
« Merge commit »
Le résultat produit par l’option Merge commit sans la case Squash cochée sera le suivant dans notre cas :
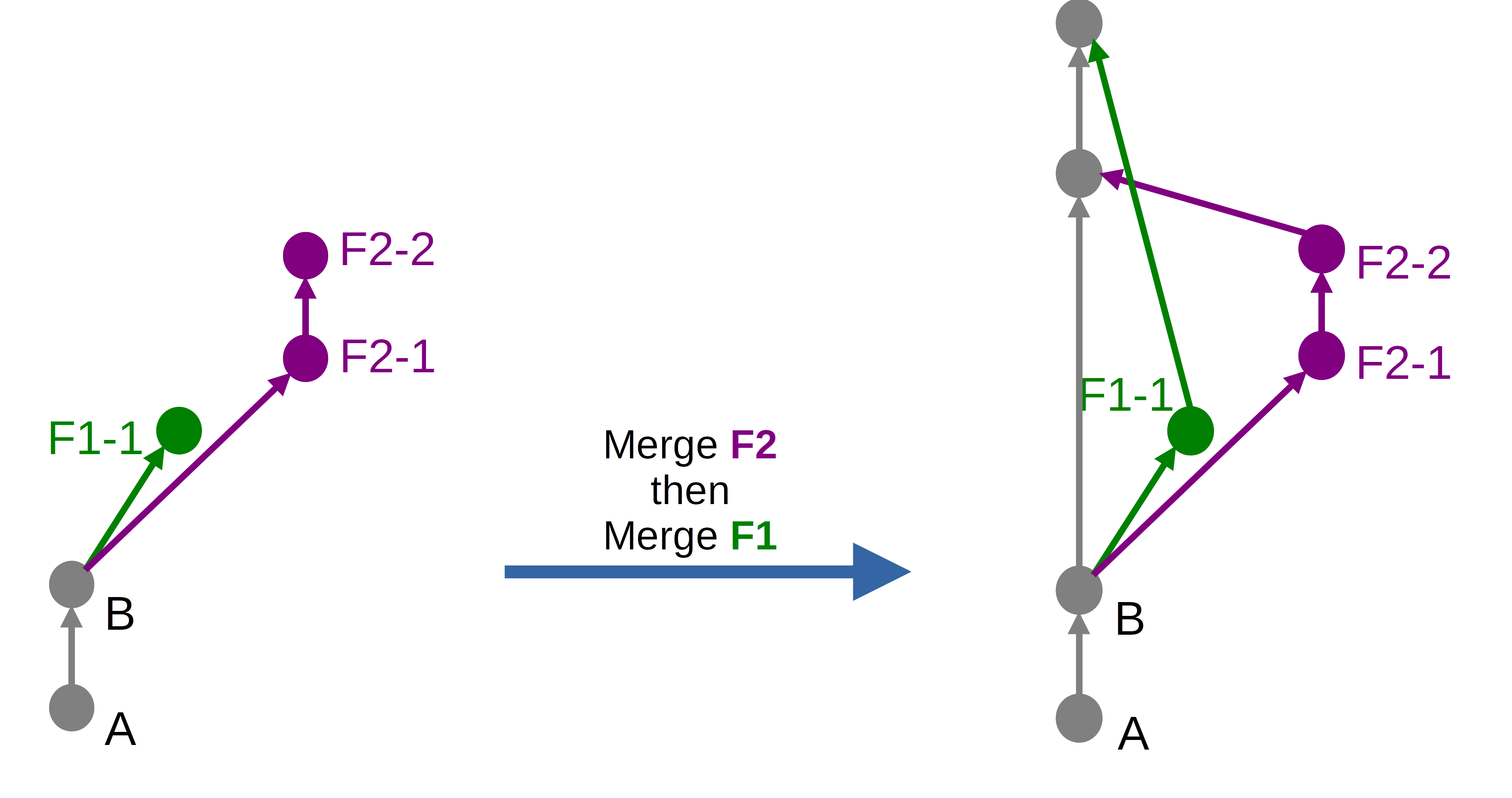
Ce résultat est le même que celui obtenu avec l’option Github « Create a merge commit ».
On observe notamment qu’un commit de merge est créé à chaque fois, même quand ce ne serait pas nécessaire, c’est-à-dire qu’un fast-forward serait possible, comme vu dans la première partie. On force donc Git à faire un commit de merge, ce qui est différent de son comportement par défaut.
La commande Git équivalente serait un git merge --no-ff, où l’option --no-ff indique de ne pas faire de fast-forward même si c’est possible.
« Merge commit » + « Squash »
Le résultat produit par l’option Merge commit avec la case Squash cochée sera le suivant dans notre cas :
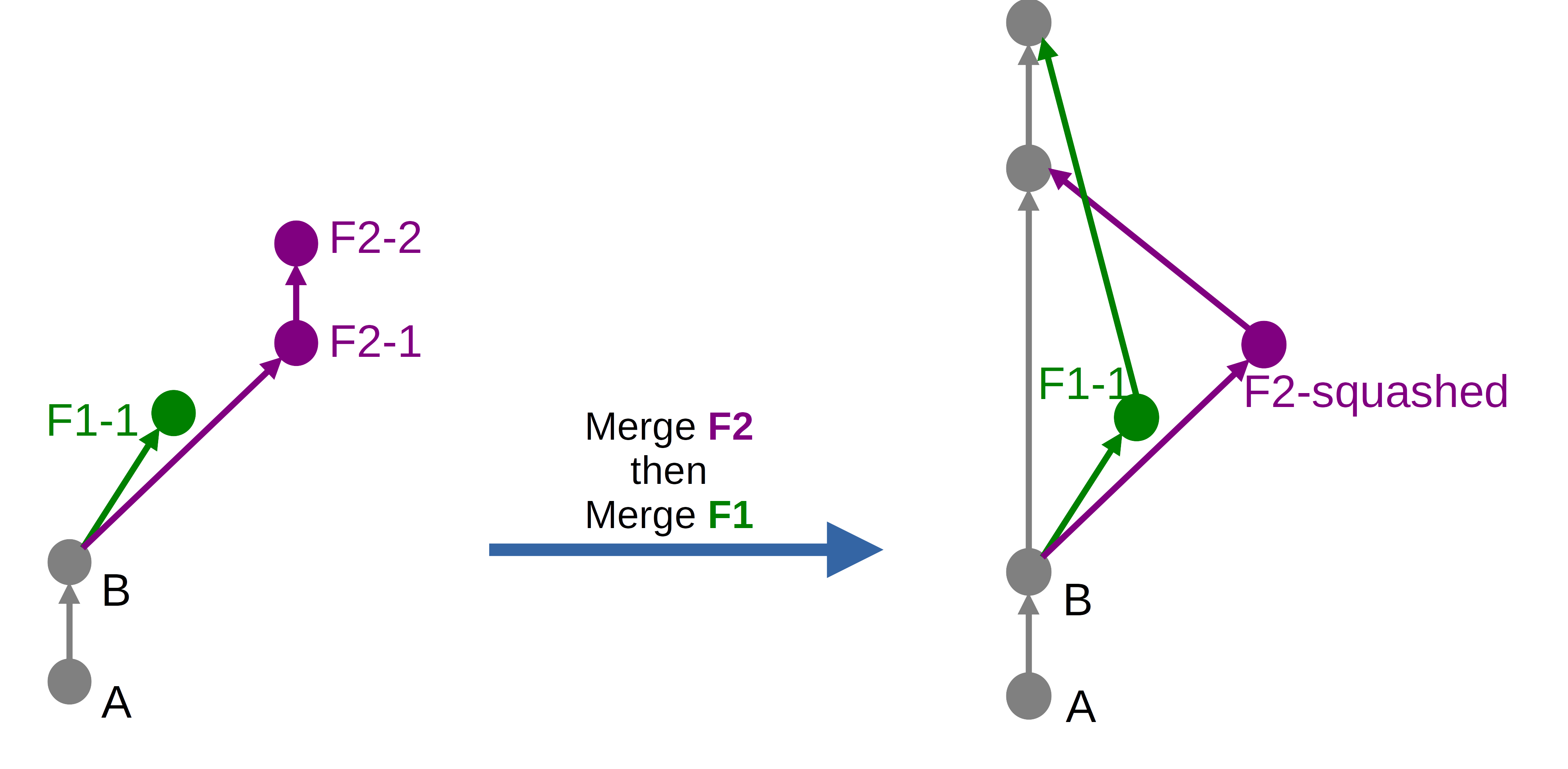
Nous avons là un résultat proche de la section précédente, à cela près que les commits de chaque branche sont fusionnés en un seul, c’est-à-dire squash, préalablement au merge.
La commande Git équivalente serait un git rebase -i suivi d’un git merge --no-ff.
« Merge with semi-linear history »
Le résultat produit par l’option Merge with semi-linear history sans la case Squash cochée sera le suivant dans notre cas :
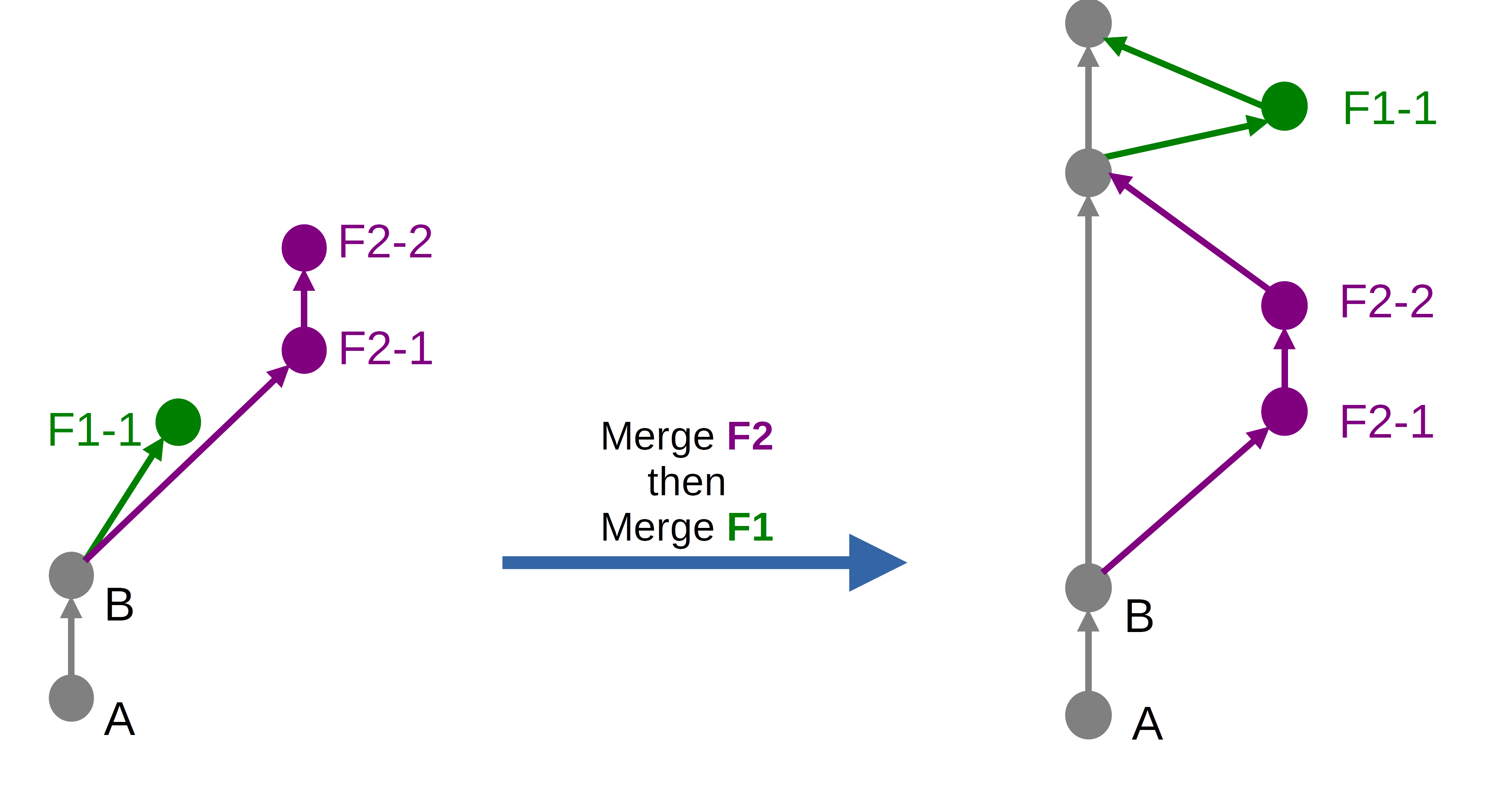
Nous avons ici un résultat qui :
- Force la création d’un commit merge, même quand ce ne serait pas nécessaire, comme l’option « Merge commit » vu plus haut ;
- Évite les « croisements » en effectuant un rebase préalable.
La commande Git équivalente serait un git rebase suivi d’un git merge --no-ff.
« Merge with semi-linear history » + « Squash »
Le résultat produit par l’option Merge with semi-linear history avec la case Squash cochée sera le suivant dans notre cas :
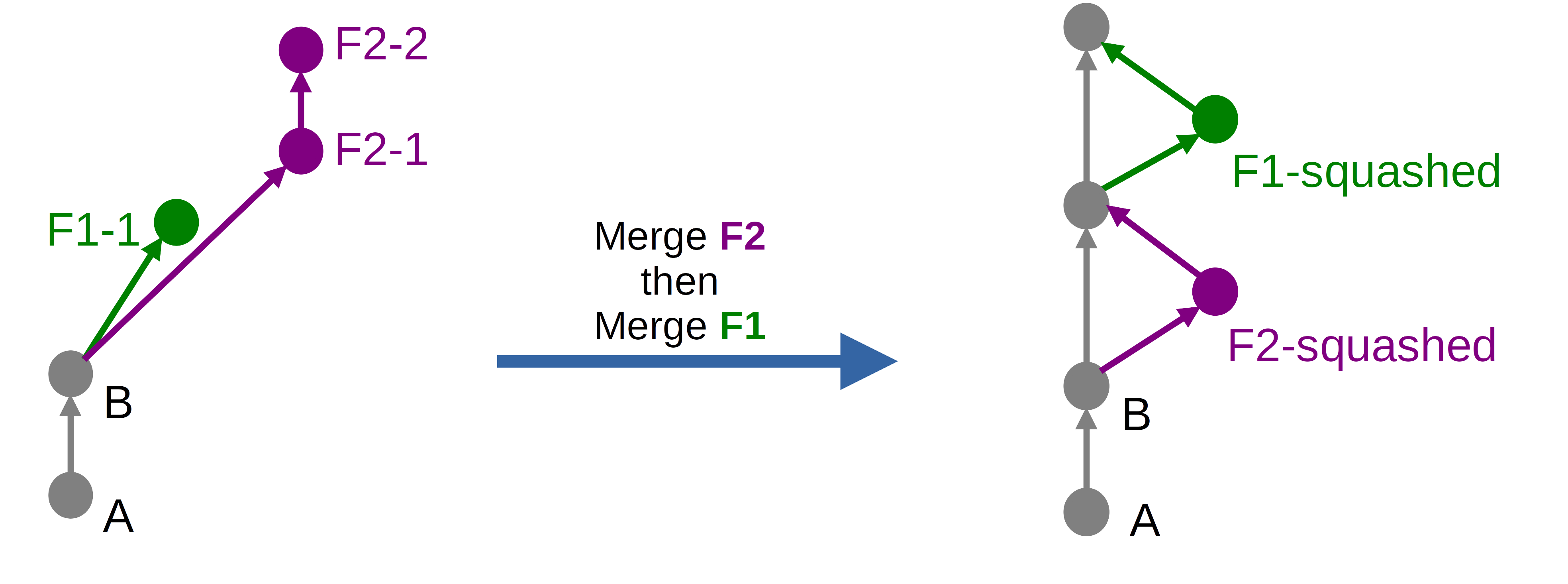
Nous avons là un résultat proche de la section précédente, à cela près que les commits de chaque branche sont fusionnés en un seul, c’est-à-dire squash, préalablement au merge.
La commande Git équivalente serait un git rebase -i --onto main suivi d’un git merge --no-ff. Le rebase -i est une commande interactive permettant notamment d’indiquer les commits à squash.
« Fast-forward merge »
Le résultat produit par l’option Fast-forward merge sans la case Squash cochée sera le suivant dans notre cas :
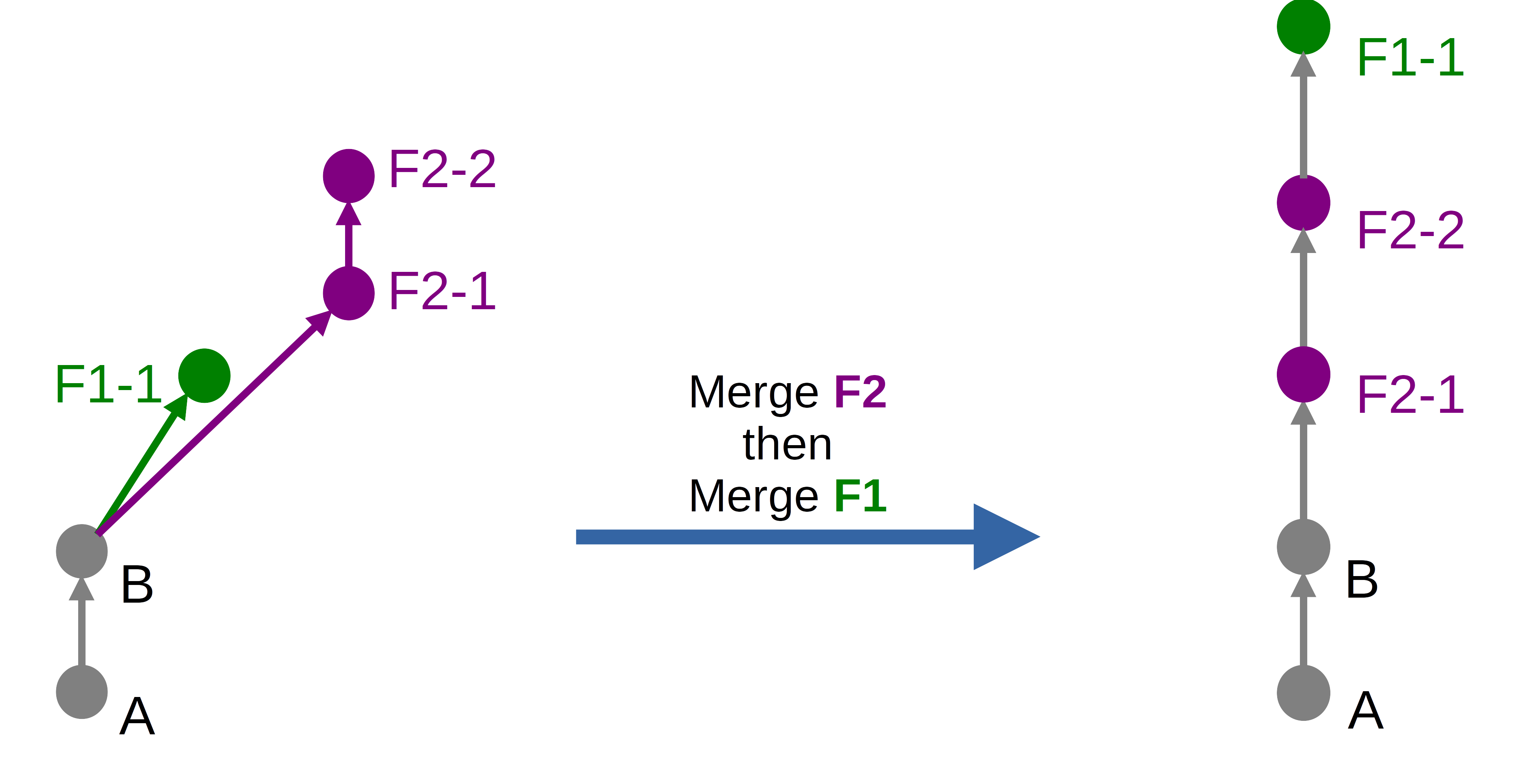
Ce résultat est le même que celui obtenu avec l’option Github « Rebase and merge ».
On observe ici 2 choses notables :
- Chaque commit non-présent sur la branche cible du merge a été déplacé au sommet actuel de celle-ci
- L’historique résultant est linéaire
La commande Git équivalente serait un git rebase (pour déplacer les commits au sommet de la branche cible) suivi d’un git merge (pour intégrer lesdits commits en fast-forward, à présent possible).
« Fast-forward merge » + « Squash »
Le résultat produit par l’option Fast-forward merge avec la case Squash cochée sera le suivant dans notre cas :
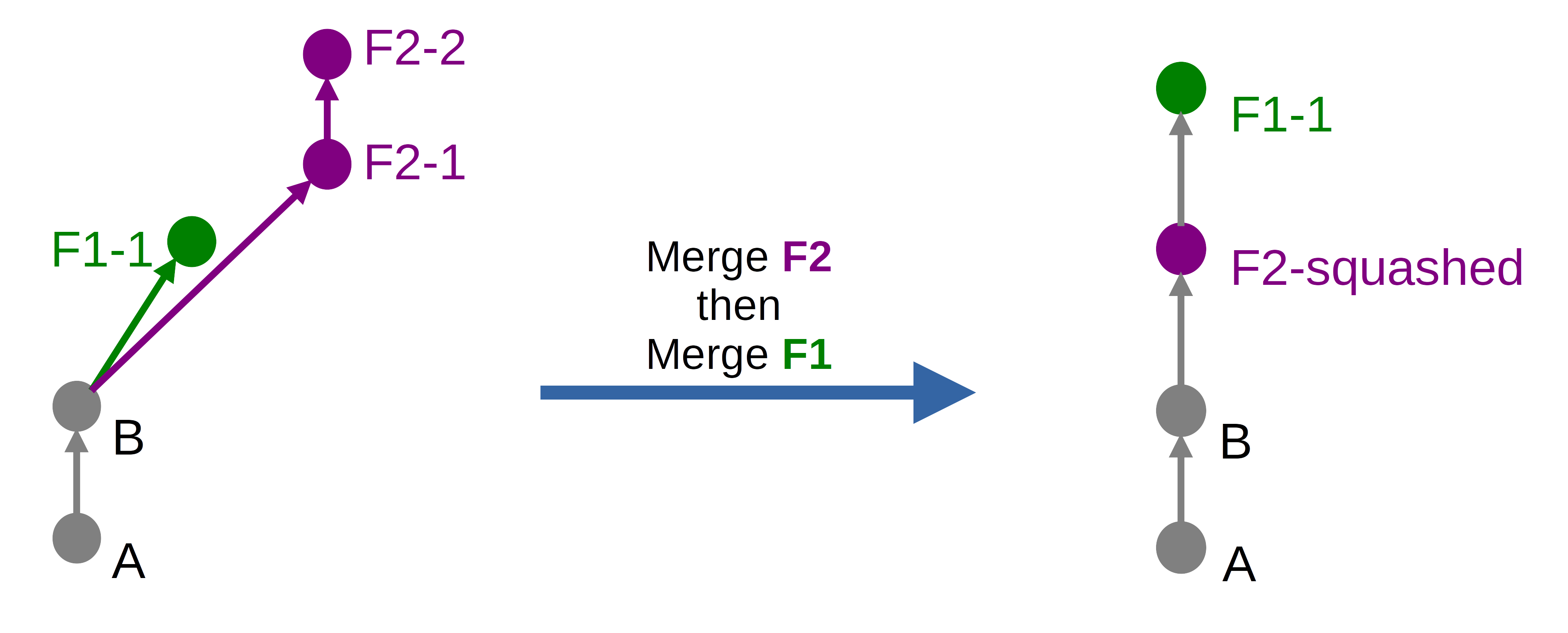
Ce résultat est le même que celui obtenu avec l’option Github « Squash and merge ».
On observe 3 choses notables :
- Les commits des branches ont été squash (quand il y en avait plusieurs)
- Chaque commit non-présent sur la branche cible du merge a été déplacé au sommet actuel de celle-ci
- L’historique résultant est linéaire et simple (1 commit par fonctionnalité)
La commande Git équivalente serait git merge --squash.
Vue d’ensemble
Au cours des 2 parties de cet article, nous avons étudié toutes les différentes possibilités de merge offertes par Github et Gitlab. Certaines sont communes aux 2 outils. Au total, il y a 6 résultats différents possibles avec ces 2 outils. Il en existe un 7e, qui n’est offert ni par Github, ni par Gitlab mais qui est disponible via la ligne de commande.
Voici une cheat sheet résumant les différents résultats possibles :
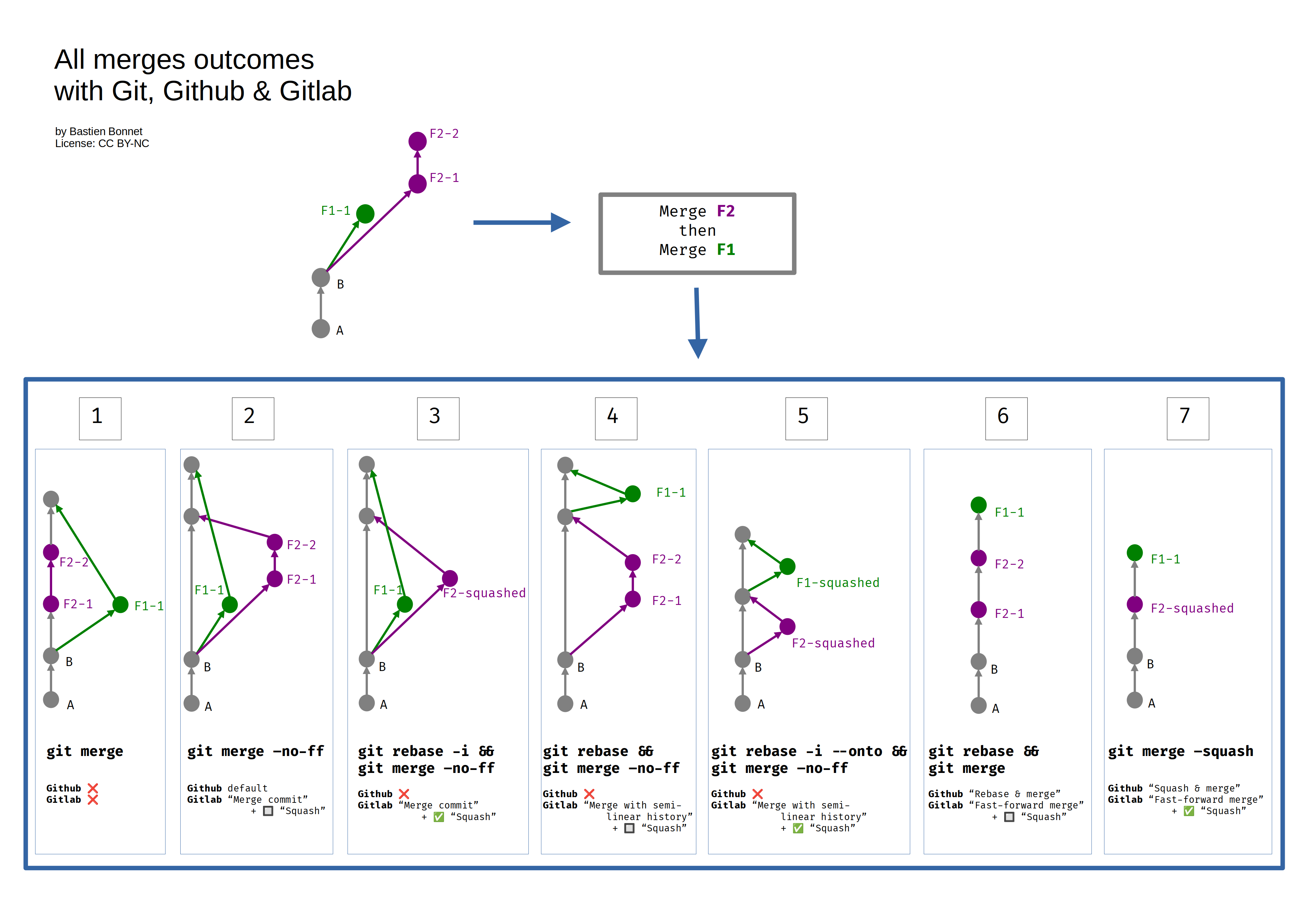
Je vais maintenant donner mon avis sur chacune des possibilités.
Hypothèses de départ
Pour l’analyse qui va suivre, je pars du principe que :
- Votre méthode de travail sur votre projet vous permet d’avoir des branches de fonctionnalité à durée de vie courte (moins d’une semaine). Si ce n’est pas le cas, il vaut mieux investir vos efforts pour avoir des User Stories plus ciblées qu’essayer de pallier le problème avec le flux de branche Git.
- Vous utilisez un flux de branches proche du Trunk-based development, ce que je vous recommande fortement. Si votre modèle est hybride (branches à durée de vie courte ET longue, comme Git Flow avec les feature branch et release branch), mes recommandations ne s’appliquent que pour les branches à durée de vie courte.
En partant de ce postulat, je considère comme un inconvénient de conserver les commits intermédiaires. En effet, je ne souhaite pas voir dans mon historique définitif des commits que j’ai pu faire pendant mon développement comme :
* Ça marche enfin !
* Add more tests
* Fix previous problem on user input parsing
* Does not compile
* Add first test
Ces commits ont pu avoir une utilité pendant mon développement. Mais après le merge, quelques semaines plus tard, ces commits ne diront rien à personne (même à leur auteur), et auront créé du bruit définitivement dans l’historique s’ils ont été intégrés tels quels.
Si vous conservez les commits intermédiaires parce que vous avez traités 2 ou plus problèmes différents dans votre branche, alors il vaut mieux faire des branches différentes (très facile avec Git, même après le début des développements) et des PR / MR séparées.
Comparaison des différentes possibilités
1 : La bonne solution s’il est nécessaire de conserver l’intégralité des informations de développement (commits intermédiaires + chronologie exacte des développements). Ce qui peut être simplifié le sera, sans aucune perte d’information.
Aussi étonnant que cela paraisse, Github comme Gitlab n’offrent pas cette possibilité via leur interface, alors que c’est le comportement de Git par défaut. Pour l’utiliser, vous devrez recourir soit à la ligne de commande, soit à un outil graphique le permettant.
→ Bonne solution si vous désirez conserver l’information de concurrence des développements ainsi que tous les commits intermédiaires (sinon faites un squash manuel avant).
2 : Cette solution est plus verbeuse que la 1 et n’apporte aucune information supplémentaire. Les commits de merge forcés n’apportent rien d’utile et au contraire ajoutent de la verbosité qui ne va pas rendre service dans le temps. Avec une équipe qui a plusieurs développements en parallèle, votre historique va rapidement ressembler à un plat de spaghettis.
De plus, cette solution présente l’inconvénient de conserver tous les commits intermédiaires.
→ Je déconseille.
3 : Par rapport à 2, on ne garde qu’un commit par fonctionnalité, ce qui est un progrès.
Les inconvénients étant les mêmes que 2., ce n’est pas le bon compromis selon moi.
→ Je déconseille.
4 : On a une historique relativement lisible (pas de croisement). Mais on conserve l’intégralité des commits.
→ Je déconseille.
5 : Pareil que 4., mais sans les commits intermédiaires. Il y a toujours l’inconvénient des commits de merge inutiles.
→ Je déconseille.
6 : Ici l’historique est linéaire, ce qui :
- Facilite la compréhension des évènements
- Facilite aussi la localisation d’anomalies, notamment si vous utilisez (et vous devriez)
git bisect.
Cependant, on conserve toujours les commits intermédiaires.
7 : Comme pour 6., mais sans l’inconvénient de conservation des commits intermédiaires.
→ C’est ma solution privilégiée qui selon moi se montrera la plus adaptée aux projets respectant le postulat de départ sur la durée des branches de fonctionnalité.
Cadeau : cheat sheet téléchargeable
Vous pouvez télécharger la cheat sheet au format PDF.
Conclusion
Nous avons vu que Git (ligne de commande), Github et Gitlab proposent des options différentes pour la résolution des merges. Seule la ligne de commande propose les 7 possibilités. Github et Gitlab n’offrent pas les mêmes possibilités et fonctionnent différemment pour le choix : choix du mode de merge lors de la PR pour Github, global à tout le projet pour Gitlab.
À moins d’avoir une solide raison, pour un développement moderne en Trunk-Based Development, je vous conseille de favoriser l’option 7, le merge --squash qui a ses équivalents sur Github et Gitlab. Cela facilitera votre lecture et compréhension de l’historique, mais aussi le debug.
N’hésitez pas à poser des questions et à lancer des discussions en réaction à cet article !
Sources images :
- Logo Git : par Jason Long — http://git-scm.com/downloads/logos, CC BY 3.0, https://commons.wikimedia.org/w/index.php?curid=19329352