Versionner des notebooks

Apprenons ensemble comment et pourquoi gérer proprement les notebooks Jupyter.

Dans l’écosystème de la Data Science, l’utilisation de notebooks est un incontournable. Pourtant, dans la plupart des projets, les notebooks sont vus comme un brouillon, quelque chose qui n’a pas sa place dans la monde du “code bien fait”. De ce fait, ils ne sont que très rarement versionnés avec la base de code principale alors qu’ils représentent une mine d’information.
TLDR
Si vous ne disposez pas de 10 minutes pour lire cet article, voici ce qu’il faut retenir :
- Utilisez toujours Jupytext sur vos installation de Jupyter locale.
- Associez tous vos notebooks à une version
percent script. - Ignorez avec
.gitignorelesipynbet versionnez les versions en.py.
Le problème des notebooks Jupyter
Un notebook Jupyter est un document JSON stocké dans un fichier texte possédant l’extension .ipynb.
Ce document possède un noeud cells contenant la liste des cellules du-dit notebook.
Chaque cellule est un document JSON qui possède tout une liste d’attributs parmi lesquels :
cell_type: le type de cellule utilisé (code, markdown, …)source: le code source de la celluleexecution_count: les cellules d’un notebook peuvent être exécutées dans n’importe quel ordre. Il s’agit du numéro de l’exécution de la cellule.outputs: la sortie de la cellule. Ici, on retrouvera différentes typologies de sorties comme du texte ou des images
Voyons maintenant deux des problèmes majeurs apportés par ce fonctionnement.
Trop de modification noie l’information
Imaginons un tel notebook versionné dans un gestionnaire de code source (type Git) et le scénario suivant. En tant que membre de l’équipe, je récupère ce notebook et l’exécute sur mon poste de travail.
Tout de suite, j’observe que les champs execution_count et outputs ont changé.
Je n’ai donc pas touché à ma base de code, mais le fichier qui gère mon code a changé.
Modifions légèrement le scénario.
Avant d’exécuter ce notebook, j’y apporte un correctif.
Une fois le correctif validé de mon côté, je vais soumettre la modification à une relecture de code par un pair.
J’ouvre donc une merge/pull requests qui va contenir mon correctif.
Le problème est qu’elle contient également un nombre important de modifications liées au rendu visuel du notebook.
Je vais donc me retrouver avec trop d’information, ce qui va noyer l’information pour la relecture par mes pairs. Leur relecture sera donc moins performante et il est fort probable que des modifications non voulues se retrouvent dans la base de code principale.
Sensibilité des données
Accordez-moi encore quelques minutes pour finir de vous convaincre de ne jamais versionner les notebooks dans ce format.
Lors d’un précédent projet, je travaillais dans le contexte d’un datalake contenant des données sensibles. La donnée est consultable par notebook. Dans un souci de sécurité, elle n’est par contre jamais ramenée sur le poste local des utilisateurs. Le serveur Jupyter est hébergé sur un serveur spécifique, dans une zone réseau protégée.
Toutes ces protections des données sensibles ont alors été balayées d’un revert de manche dès lors qu’un notebook a été versionné.
Il a été versionné avec ses champs outputs.
Cela a eu pour effet de déposer sur le serveur Git, donc en dehors de la zone réseau protégée, une partie de la donnée sensible qui était dans ces champs outputs.
Un remède à la racine du problème
Tous les problmèmes évoqués plus haut ont une cause commune: Jupyter stocke, dans ses fichiers .ipynb, le code ET le contexte d’exécution.
C’est bien là la grande différence que l’on a avec le code tel qu’il est versionné dans le reste du monde informatique.
Un remède a cette cause racine existe et nous allons entrer en détail dans son fonctionnement : Jupytext.
Présentation de Jupytext
Jupytext est un plugin de Jupyter qui permet de synchroniser ses notebooks avec des équivalents stockés dans d’autres formats.
Le format qui nous intéressera ici est le .py.
- Tout d’abord, commençons par une installation du plugin.
Depuis l’environnement python qui contient votre installation de Jupyter, lancer la commande suivante:
pip install jupytextRedémarrez ensuite votre instance de Jupyter et le tour est joué.
Jupytext est alors disponible sous forme de commande si vous utilisez JupyterLab ou sous forme de menu (dans le menu
File) si vous utilisez Jupyter. - Ouvrez le notebook qui vous intéresse (ici un fichier
.ipynb). Lancez la commande (ou le menu suivant votre installation Jupyter)pair notebook with percent script
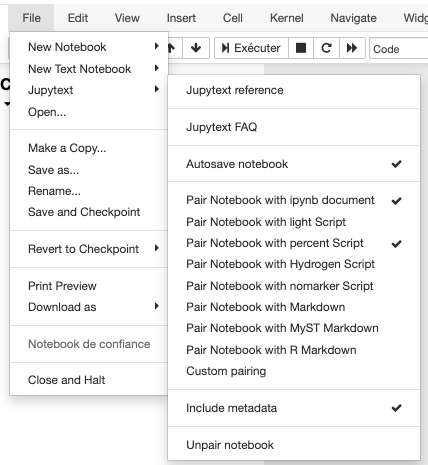
</div>
Vous verrez apparaître un fichier .py portant le même nom que le notebook juste à côté de ce dernier.
Si vous éditez le fichier .ipynb, cela va mettre à jour le fichier .py en conséquence.
Lorsque vous choisirez d’ouvrir le fichier .py dans Jupyter, ce dernier ouvrira le notebook avec le rendu habituel.
La seule différence sera que tous les outputs sont effacés (le fichier .py n’embarque pas ces outputs).
Il conviendra alors de ne plus versionner les .ipynb mais seulement le .py.
Pour cela, rien de plus simple, il suffit d’ignorer ces fichiers dans votre gestionnaire de version.
Voici le fichier .gitignore que je place en général dans mes répertoires de notebooks.
*.ipynb
.ipynb_checkpoints
Maintenant, vos merge / pull requests seront plus lisibles !
Bénéfice collatéral
Ce type d’installation apporte un bénéfice collatéral pour les utilisateurs de Jupyter en local (depuis leur poste de travail).
Puisque les notebooks sont versionnés, ils sont dans l’arborescence de votre projet. S’ils sont dans cette arborescence, ils sont visibles par votre IDE préféré.
Du simple fait que votre IDE puisse les considérer en tant que fichier source Python, si vous effectuez un refactoring, l’IDE pourra alors mettre à jour le code dans votre notebooks automatiquement !
Conclusions
Jupytext est un outil simple d’installation, simple d’utilisation et qui permet d’éviter de nombreux eccueils. Il s’agit sans aucun doute de ma meilleure découverte d’outil de 2020 sur le plan technique !
Cependant, ne soyons pas obtus non plus.
Versionner un fichier au format .ipynb a tout de même un avantage.
De plus en plus, les outils comme Gitlab ou Github incluent des interpréteurs ipynb pour afficher un rendu propre en mode web.
En versionnant uniquement le fichier .py, on perd alors cette fonctionnalité.
Il existe donc quelques cas où versionner un fichier au format .ipynb sera tout de même recommandé.
Citons par exemple les notebooks à des fins de formation.
Je n’ai qu’une chose à vous dire pour terminer cet article : sautez le pas et versionnez vos notebooks.