XGBoost, LightGBM, CatBoost :
lequel choisir ?

Comparaison de leurs fonctionnalités et de leurs performances sur quelques datasets

Si le Deep Learning a aujourd’hui la cote quand il s’agit de classifier des articles ou de générer des images, le traitement des données tabulaires reste quant à lui dominé par les algorithmes de Gradient Boosting. Et, en python, trois bibliothèques dominent le marché en terme d’utilisation : XGBoost, LightGBM et CatBoost.
Nous allons ici chercher à avoir un aperçu des principales différences entre ces trois implémentations, et à voir si l’on peut trouver des critères pour décider sur l’implémentation à tester en priorité en fonction de la situation.
Historique et popularité
Lancé initialement en mars 2014, XGBoost est, parmi les trois bibliothèques considérées, celle qui est la plus ancienne et qui a aujourd’hui acquis le plus grand nombre d’utilisateurs. Si XGBoost apporte de nombreuses améliorations par rapport à l’implémentation de sklearn, la principale différence qui l’a rendue célèbre et a permis au Gradient Boosting de vraiment prendre son essor est sa durée d’entraînement bien plus faible que celles des implémentations précédente.
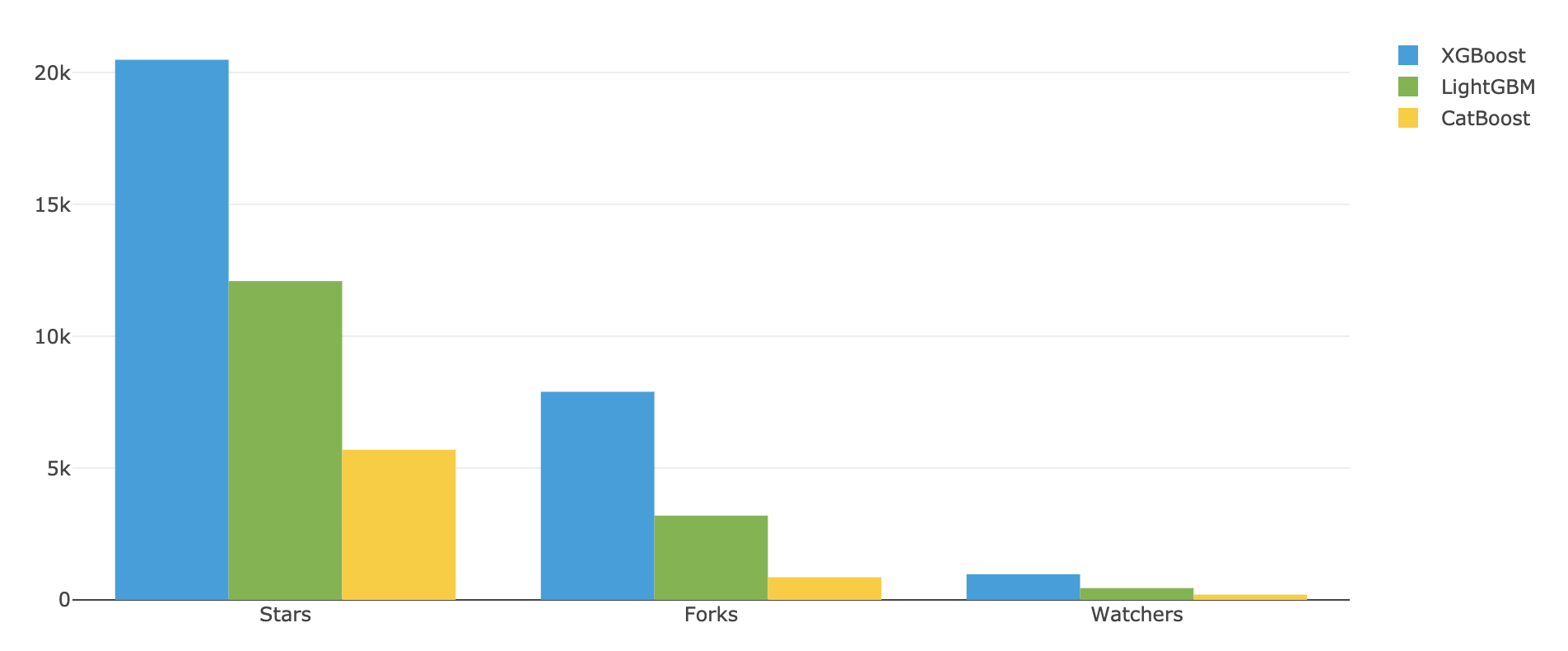
En octobre 2016, à la suite de l’explosion de popularité de XGBoost, Microsoft a open-sourcé une nouvelle implémentation du Gradient Boosting : LightGBM. En mettant un focus encore plus grand sur la rapidité et la consommation mémoire, cette dernière bibliothèque a réussi à se tailler une part de marché non négligeable, bien que toujours inférieure à celle de XGBoost.
CatBoost, enfin, a été lancé en juillet 2017 par la compagnie russe Yandex. Bien qu’elle soit restée très en deçà de ses deux concurrents en terme d’utilisation, cette bibliothèque a tout de même réussi gagner sa part de lumière sur le marché des modèles de Gradient Boosting, notamment grâce à ses multiples fonctionnalités, et au traitement facilité des variables catégorielles qu’elle offre.
Des implémentations légèrement différentes
Je ne m’attarderai pas ici sur l’intégralité des différences d’implémentation entre les trois modèles. Chacun a cherché à optimiser les temps d’entraînement et de prédiction, sans pour autant dégrader les performances. Vous pourrez retrouver des comparatifs plus détaillés ici ou là si vous avez envie de plus creuser le sujet.
| XGBoost | LightGBM | CatBoost | |
|---|---|---|---|
| Construction des arbres | Par niveau ou par feuille | Par feuille | Par niveau (Arbres symétriques) |
| Algorithme de pondération des échantillons pour la segmentation sur les grands datasets | Aucun | Gradient-based One-Side Sampling (GOSS) | Minimum Variance Sampling (MVS) |
| Variables catégorielles | Non-supportées (à traiter séparément) | À encoder numériquement et indiquer lors de l’entraînement (segmentation intelligente) | À indiquer lors de la création du modèle (dummification ou target encoding automatique en fonction de la taille du dataset) |
| Calcul de l’importance des variables | Gain moyen sur la fonction de coût suite au noeuds où la feature est utilisée | Nombre de noeuds où la feature est utilisée | Valeur moyenne du changement de prédiction lorsqu’un changement de la valeur de la feature change la prédiction finale |
Il est toutefois intéressant de noter que chacune de ces bibliothèques implémente de nombreux algorithmes que je n’ai pas forcément cités ci-dessus, ainsi que des heuristiques permettant de choisir automatiquement l’un ou l’autre des algorithmes en fonction de la nature des données en entrée. Cela permet d’améliorer les performances des algorithmes sans demander à l’utilisateur de faire trop de choix, mais cela entraîne aussi une certaine complexification de la documentation, et une difficulté pour un utilisateur avancé à prendre en compte l’ensemble des options possibles lors des phases d’optimisation des hyperparamètres.
Pas de vainqueur au niveau des performances
Afin de pouvoir comparer les performances et les temps d’entraînements des trois modèles cités, j’ai développé un petit programme que vous pouvez récupérer, modifier et exécuter à votre guise. J’y ai utilisé huit datasets publics, dont la taille varie de quelques centaines d’échantillons à plusieurs centaines de milliers, possédant entre 0 et 85% de variables catégorielles, et jusqu’à 1200 catégories possibles. Vous pouvez voir les résultats complets des comparaisons présentées ci-dessous dans ce notebook, ainsi que quelques autres tests que je n’ai pas jugés intéressant de présenter ici (notamment liés à l’utilisation de l’encodeur catboost).
Afin de mesurer la performance des différents algorithmes, j’ai calculé par validation croisée un score de performance pour chaque modèle, avant et après optimisation des hyperparamètres. Ce score de performance correspond :
- au coefficient de détermination R2 pour les tâches de régression ;
- à la précision moyenne pour les tâches de classification.
L’optimisation des hyperparamètres a été faite avec optuna. Jusqu’à 300 combinaisons d’hyperparamètres ont été testés pour chaque modèle, avec un système d’early stopping au cas où optuna n’arriverait pas à améliorer le score pendant 100 itérations consécutives.
J’ai ensuite pondéré les différents résultats en fonction du score correspondant du modèle XGBoost entraîné avec ses paramètres par défaut. On obtient alors les résultats suivants :
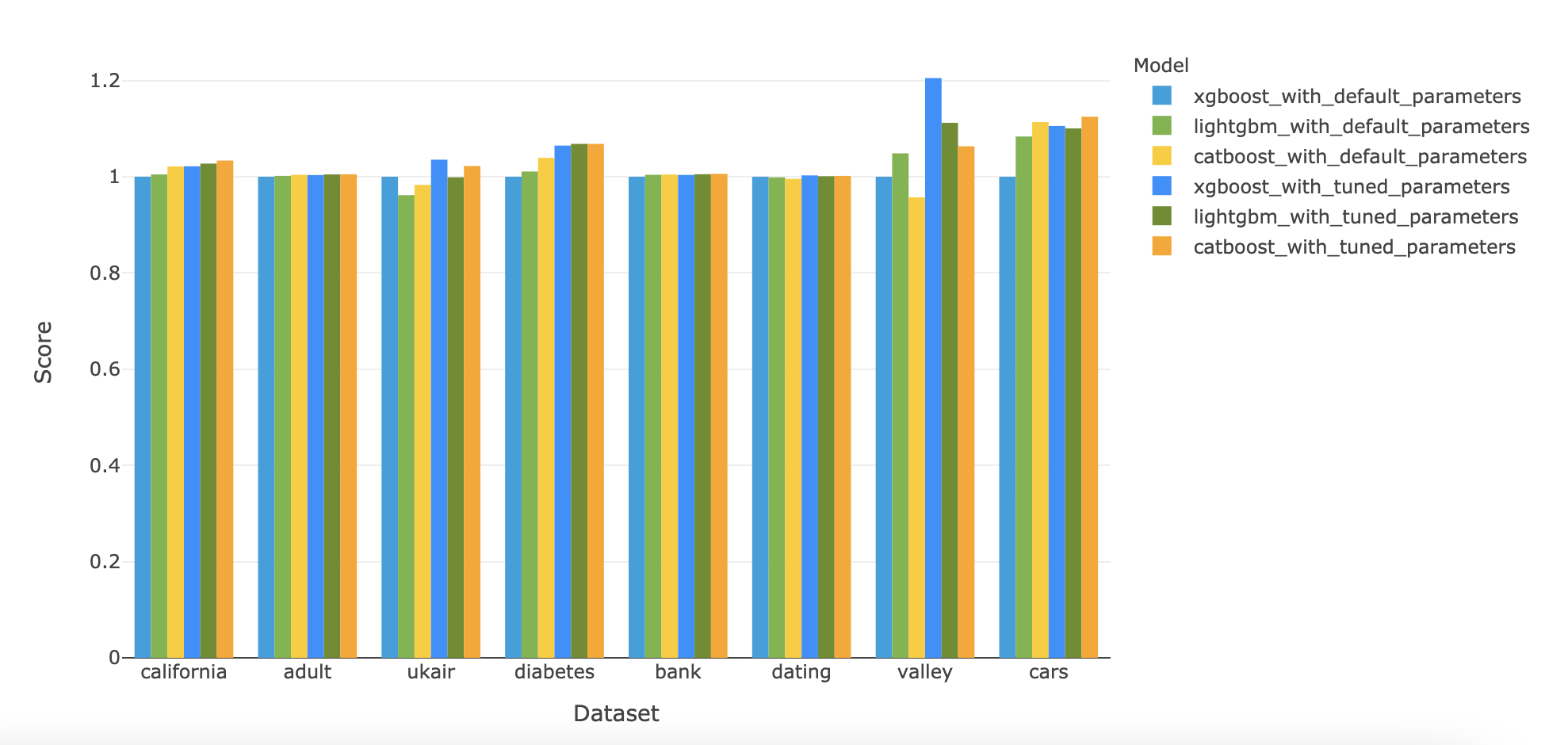
Ce que l’on remarque, c’est que d’une part les différences entre les scores des différents modèles sont souvent assez faibles, mais de temps en temps significatives (notamment pour les datasets cars et valley) ; et, d’autre part, l’ordre entre les scores des différents modèles dépend lui aussi fortement du dataset utilisé. Une analyse du score médian par modèle permet néanmoins de se rendre compte que, en l’absence d’optimisation des hyperparamètres, le score de XGBoost est souvent légèrement inférieur à celui de CatBoost ou LightGBM. Mais, après optimisation, c’est plutôt LightGBM qui a le plus souvent un score inférieur à celui des autres modèles :
| XGBoost | LightGBM | CatBoost | |
|---|---|---|---|
| Score médian avant optimisation des hyperparamètres | 1,0 | 1,004 | 1,004 |
| Score médian après optimisation des hyperparamètres | 1,029 | 1,016 | 1,028 |
Un modèle qui se démarque au niveau de la rapidité d’entraînement
Un autre point important concerne le temps d’entraînement et de prédiction. Et si pour les temps de prédiction, le jeu est une nouvelle fois assez égal entre les trois modèles (avec toutefois des variations assez fortes, et un temps médian un tiers plus faible pour catboost et lightgbm par rapport à xgboost), la différence est bien plus importante concernant les temps d’entraînement. En effet, LightGBM est dans ce domaine très loin de ses deux concurrents, avec un temps d’entraînement plus de 100 fois plus rapide (ce qui m’a d’ailleurs forcé à adopter une échelle logarithmique dans les diagrammes ci-dessous) :
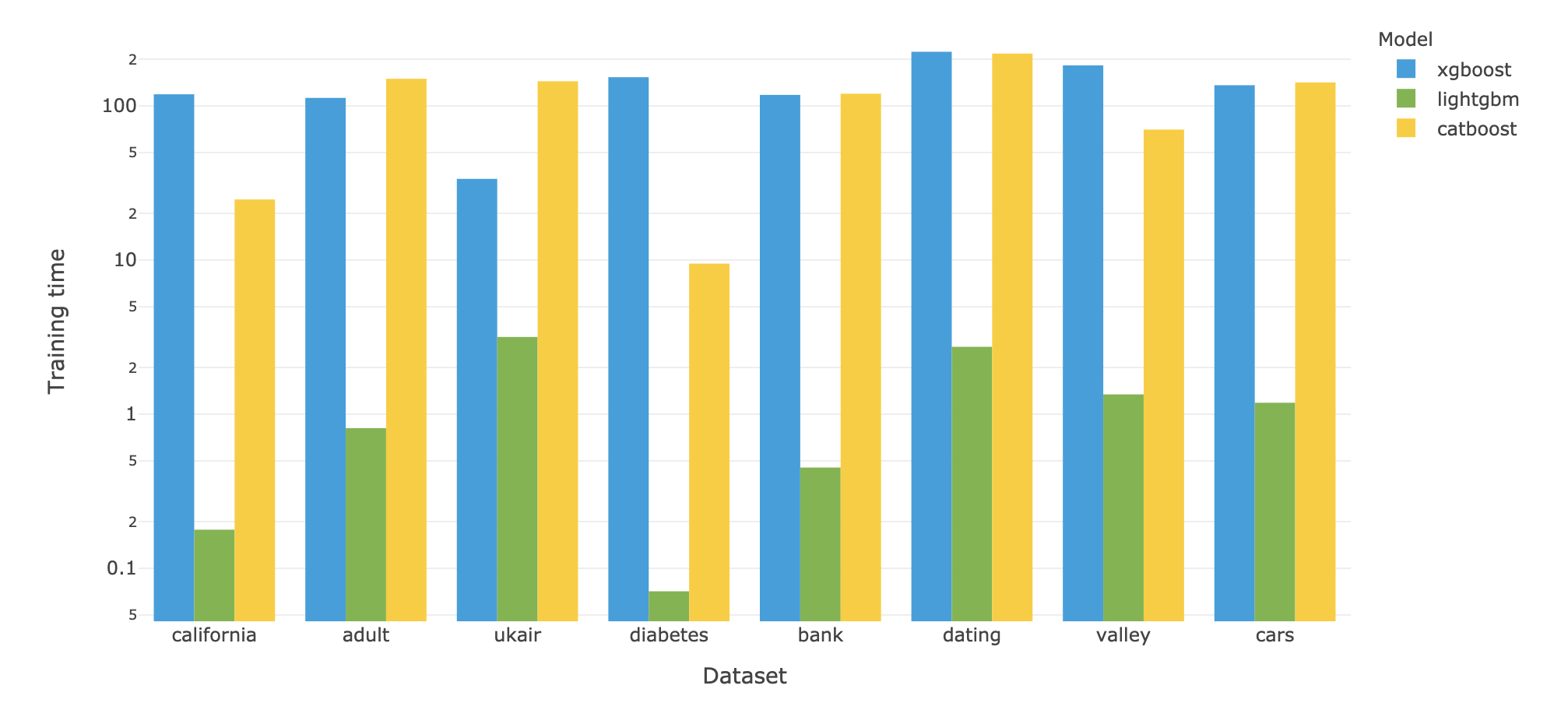
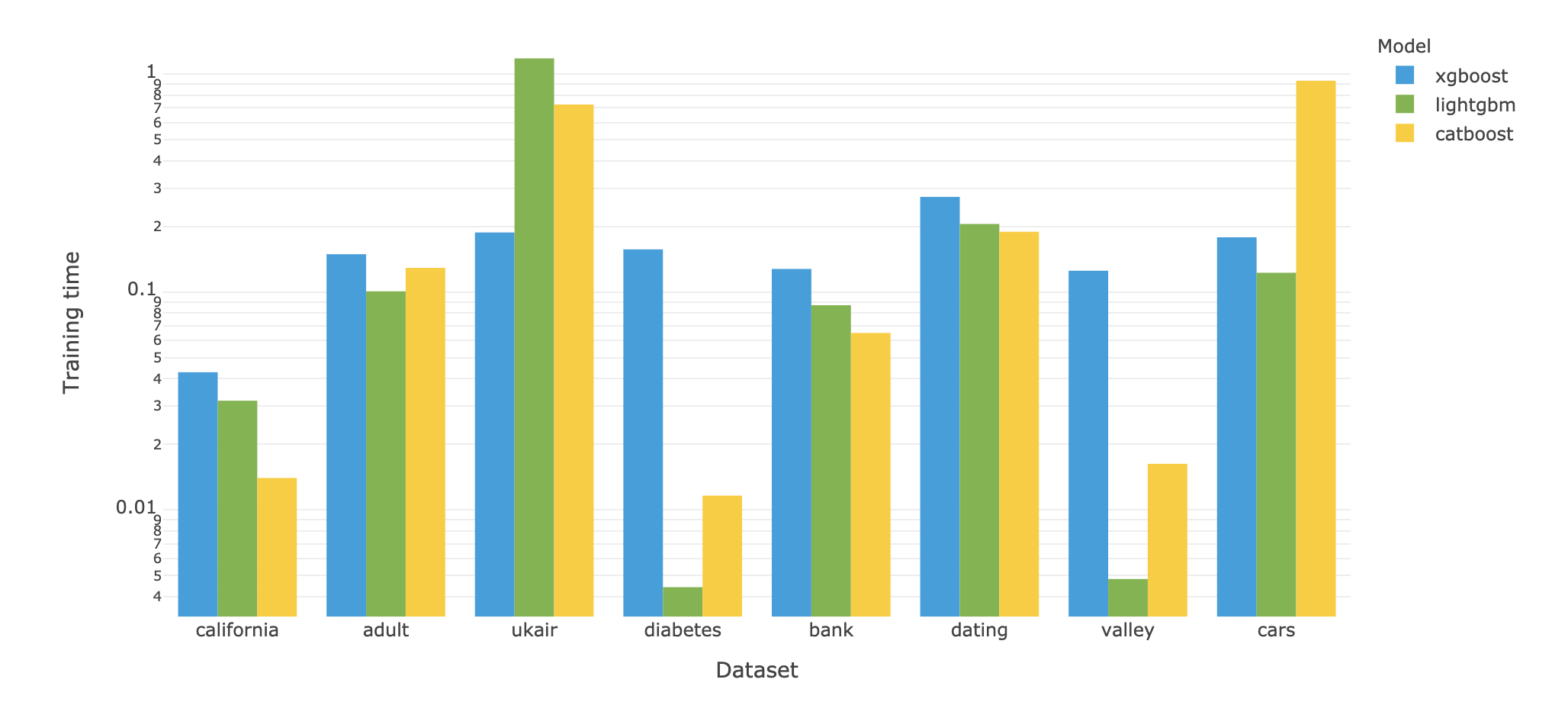
Il faut toutefois noter que ces temps ont été mesuré avec les paramètres par défaut des modèles, qui peuvent être assez différents d’un modèle à l’autre et expliquer une partie des différences. CatBoost entraîne notamment 1000 arbres par défaut, contrairement à LightGBM et XGBoost qui n’en entrainent que 100. Mais les quelques différences ne semblent pas modifier l’ordre général qui se dessine ici, et qui fait de LightGBM le plus rapide des modèles, et de XGBoost le plus lent.
| XGBoost | LightGBM | CatBoost | |
|---|---|---|---|
| Temps d'entraînement médian ramené à celui de XGBoost | 1,0 | 0,007 | 0,996 |
| Temps de prédiction médian ramené à celui de XGBoost | 1,0 | 0,60 | 0,68 |
Conclusion
| XGBoost | LightGBM | CatBoost | |
|---|---|---|---|
| Popularité |
|
|
|
| Gestion automatique des variables catégorielles |
|
|
|
| Performance en l'absence d'optimisation des hyperparamètres |
|
|
|
| Performance après optimisation des hyperparamètres |
|
|
|
| Rapidité d'entraînement |
|
|
|
| Rapidité de prédiction |
|
|
|
Voici les différents cas d’utilisation que je recommanderais suite aux résultats de ce comparatif :
- si vous souhaitez obtenir des résultats et itérer rapidement, et que votre dataset est relativement gros, ou que vous n’avez pas envie d’attendre plusieurs minutes que s’effectuent chacun de vos entraînements, choisissez LightGBM ;
- si vous souhaitez obtenir des résultats et itérer rapidement, et que votre dataset est relativement petit et comporte plusieurs variables catégorielles importantes que vous n’avez pas envie de traiter, choisissez CatBoost ;
- si le plus important pour vous est d’obtenir les meilleures performances possibles quitte à y passer plus de temps, testez les trois modèles ;
- si vous comptez intégrer votre modèle en production et souhaitez un modèle dans lequel vous pouvez avoir le plus confiance du fait de son ancienneté et de sa popularité, choisissez XGBoost.
Datasets utilisés
- le dataset California Housing, qui s’intéresse au prix moyens des maisons dans les différents districts de Californie
- le dataset Adult, où l’on cherche à prédire si une personne gagne plus ou moins de 50K$ par an
- le dataset particulate-matter-ukair-2017, qui recense le taux de particule dans l’air dans différents endroits du Royaume-Uni au cours de l’année 2017
- le dataset Diabetes, qui recense la prévalence du diabète auprès de 768 femmes amérindiennes d’Arizona
- le dataset bank-marketing, qui cherche à prédire si un client va ou non souscrire à un produit bancaire suite à une action marketing
- le dataset SpeedDating, qui cherche à prédire si deux personnes déclarent souhaiter se rencontrer suite à une rencontre de Speed Dating
- le dataset hill-valley, où l’on cherche à déterminer si les coordonnées de 100 points d’un terrain particulier représentent une colline ou une vallée
- le dataset Used cars, où l’on cherche à prédire la dureée que prendra un véhicule d’occasion avant d’être revendu sur la plateforme Craigslist
Une réaction ? Contribuez à cet article en laissant un commentaire :
Les commentaires de nos lecteurs :
-
Publié par
ydoha
,le 08/03/2022
:Très intéressant, Merci beaucoup